
The most important thing for ML development - Overfitting/Underfitting with visualization
Do you know overfitting and underfitting?

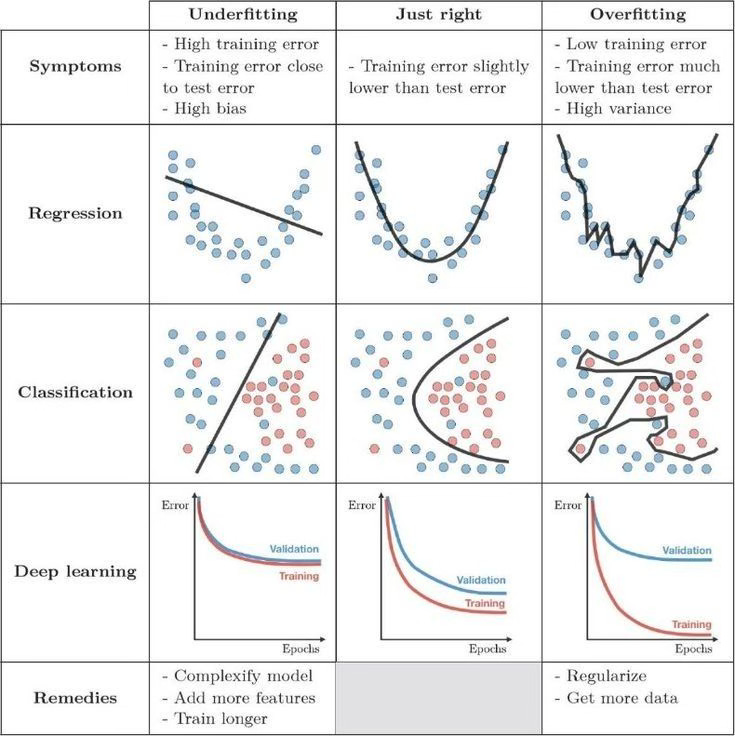
https://www.kaggle.com/discussions/getting-started/166897
Navigating the ML Zone: Mastering Overfitting and Underfitting in Machine Learning
Machine learning is all about balance—just like life itself. Finding that perfect point between too little and too much makes all the difference. Let's unpack two critical pitfalls: overfitting and underfitting, and discover how to strike the right balance.
Overfitting: When Your Model Learns Too Much
Imagine studying for an exam. You memorize every tiny detail, from footnotes to doodles in your margins. Come test day, you confidently realize you've memorized everything—except the actual mainpoints. This is exactly what happens in overfitting.
In machine learning, overfitting occurs when your model learns your training data too well, picking up even irrelevant details. While your model performs brilliantly during training, it struggles to handle new data, much like a student blindsided by unexpected exam questions.
Underfitting: When Your Model Doesn't Learn Enough
Now, imagine baking a cake but choosing to skip crucial steps out of impatience. The result? A half-baked mess that's barely edible. Welcome to underfitting.
Underfitting occurs when a machine learning model is overly simplistic. It doesn't learn enough from the training data and ends up performing poorly across the board—just like your unfinished cake that no one wants to taste.
Striking the Perfect Balance: Just Right
Mastering machine learning is similar to perfecting your favorite recipe—follow the essentials but leave room for creativity. Your model should grasp the essential patterns without obsessing over every detail.
Real-Life Scenarios
Consider movie recommendations. An overfitting system might obsess over every quirky film you've watched, recommending irrelevant choices based on isolated incidents. An underfitting system, meanwhile, blindly suggests random movies, ignoring your genuine preferences.
Or take weather forecasting. An overfitting model might try predicting tomorrow’s temperature based on the exact time you opened your umbrella last week, while an underfitting one might lazily predict the same temperature every day, disregarding seasonal changes entirely.
Tips to Avoid Overfitting and Underfitting
Cross-Validation: Test your model across multiple subsets of data to ensure it isn't overly dependent on one specific dataset.
Feature Selection: Focus only on relevant data points. Don't overload your model with unnecessary information, but ensure you include essential insights.
Regularization: Implement constraints that keep your model from overcomplicating itself—think of this as adding just enough seasoning to your recipe.
Increasing Data Volume: Adding more diverse data helps your model better recognize underlying patterns, making it robust and versatile.
Managing Model Complexity: Be cautious about excessively complex models. Simplify when needed by reducing unnecessary layers or parameters to enhance generalization.
Wrapping It Up
Just like cooking or preparing for a test, success in machine learning hinges on finding balance. Avoid the temptation to overcomplicate or oversimplify. Aim for the "just right" zone—creating accurate, reliable models ready to tackle real-world challenges. Happy machine learning!